![[논문리뷰] Sequence to Sequence Learning with Neural Networks](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FoZf6e%2FbtrvDgMwHdu%2FAAAAAAAAAAAAAAAAAAAAAKOChOLWyNi2w9GKIwNzTbYM-iE_kGqqLqx8gQd492SG%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DlkTHNrbx3xao3SYguMfyOeDobgc%253D)
본 게시물은 Sequence to Sequence Learning with Neural Networks를 요약 및 번역 정리한 내용입니다.
0. Abstract
- 어려운 학습 과제에도 좋은 성과를 내는 Deep Neural Networks(DNNs)는 대용량의 지도 학습 데이터셋에는 잘 적용되지만 시퀀스를 잇는(mapping) 학습에는 사용될 수 없다.
- 시퀀스 학습의 일반적인 end-to-end 접근법을 제안하고자 한다. 해당 접근법은 시퀀스 구조에 대해 최소한의 추정을 하는 방법이다.
- 입력 시퀀스를 고정된 차원의 벡터로 매핑하기 위한 다층의 Long Short-Term Memory (LSTM)을 사용한다.
- 벡터로부터 타겟 시퀀스를 디코딩하는 또 다른 다층의 LSTM을 사용한다.
- 논문에서 사용할 태스크는 영어-프랑스어 번역이다. (데이터셋 : WMT' 14 dataset)
- 모델 평가는 BLEU 스코어를 이용한다.
- 타겟 문장을 제외한 입력 문장의 단어 순서를 뒤집는 것이 LSTM의 성과를 개선한다는 것을 발견했다.
- 단어 순서를 뒤집으면서 인풋 문장과 타겟 문장 사이에 많은 의존도를 도입하게 되고, 이로 인해 문제를 최적화할 수 있었다.
1. Introduction
1) Deep Neural Networks(DNNs)
- 음성 인식, 사물 인식 등의 어려운 문제에 대해 좋은 성능을 갖고 있는 모델
- 적당한 단계의 임의의 병렬 계산이 가능하기 때문
- 이차 크기의 히든 레이어 2개만을 사용해 N-비트의 수를 정렬할 수 있다.
- 대형 DNNs은 label된 학습 셋이 네트워크의 파라미터를 구체화할 수 있을 정도의 충분한 정보를 갖고 있다면,
지도 역전파를 이용해 학습시킬 수 있다. - 하지만, 입력과 타겟이 고정된 차원의 벡터로 인코딩 된 문제에만 적용할 수 있다는 한계가 있다.
2) sequential problems
- 음성 인식, 기계 번역 등 많은 문제들은 길이를 알 수 없는 시퀀스로 잘 표현된다.
- question-answering 문제는 질문을 대표하는 단어들의 시퀀스를 정답을 대표하는 단어들의 시퀀스로 매핑해야 한다.
- 위와 같은 문제처럼 영역에 구애받지 않으면서 시퀀스를 시퀀스로 매핑하는 것을 학습하는 방법이 유용하다는 것을 알 수 있다.
- DNNs는 입력과 출력의 차원을 알 수 있어야 하며, 고정되어야 하기 때문에 시퀀스를 해결하기에는 어려움이 있다.
- 이 논문에서 Long Short-Term Memory (LSTM) 아키텍처가 일반적인 sequence to sequence 문제를 해결할 수 있다는 것을 보여주고자 한다.
3) Idea with Long Short-Term Memory (LSTM)
- 입력 시퀀스를 읽는 데에 LSTM을 한 번 사용한다.
- 이를 통해 고정된 차원의 벡터 표현을 얻을 수 있다.
- 또 다른 LSTM을 이용해 벡터에서 출력 시퀀스를 추출한다.
- 두 번째 LSTM은 recurrent neural network 언어 모델이다.
- LSTM은 입력과 입력에 대응하는 출력 사이의 시간 차로 인해 긴 범위의 일시적인 의존성을 학습한다.

3. The model
1) RNN의 한계
입력 시퀀스가 주어지면, Recurrent Neural Network (RNN)은 출력 시퀀스를 아래 수식을 이용해 계산한다.

- RNN은 입력과 출력 사이의 정렬을 미리 알 수 있을 때마다 시퀀스와 시퀀스를 쉽게 매핑할 수 있다.
- 그러나, 입력과 출력 시퀀스가 서로 다른 길이를 갖고 있는 문제에 대해 적용하는 방법이 명확하지 않다.
- 일반적인 시퀀스 학습을 위한 가장 간단한 전략은 하나의 RNN을 사용해 입력 시퀀스를 고정 사이즈의 벡터로 매핑하고, 또다른 RNN을 사용해 벡터를 타겟 시퀀스로 매핑하는 것이다.
- 하지만 이 방법은 Long term dependency라는 문제를 야기할 수 있다.
- Long Term Dependency (장기 의존성 문제) : 1보다 작은 값을 반복적으로 곱하는 수식이기 때문에 문장이 길어질수록 앞의 정보를 뒤까지 전달하기 어려운 문제가 일어난다.
- 따라서 Long term dependency 문제를 해결할 수 있는 LSTM으로 해당 문제를 학습해보고자 한다.
2) LSTM
- LSTM은 길이가 서로 다른 입력 문장과 출력 문장의 조건부 확률을 추정한다.
- LSTM의 마지막 히든 스테이트에서 나온 입력 문장의 고정된 차원적 표현인 v를 구함으로써 조건부 확률을 계산한다.
- 초기 히든 스테이트가 v로 설정된 표준 LSTM-LM 공식을 사용해 출력 문장의 확률을 계산한다.
- 각 분포는 단어 사전 안에 있는 모든 단어의 소프트맥스 값으로 표현된다.
- 각 문장은 end-of-sentence 상징인 "<EOS>" 토큰으로 끝난다.
- 이 토큰을 이용해 문장의 끝을 알 수 있다.
- 입, 출력 문장 모두 해당 토큰으로 끝난다.
3) 모델 특징
- 입력 문장, 출력 문장에 해당하는 두 개의 다른 LSTM 모델을 사용한다.
> 두 개의 모델을 사용하는 것이 계산되는 모델 파라미터 수가 미미한 정도로 늘어나고, 복수의 언어를 동시에 학습시키는 것이 더 자연스럽기 때문이다. - 좁은 LSTM 보다 넓은 LSTM이 두드러지게 좋은 성과를 냈다는 것을 알아냈다.
> 4개 층의 LSTM을 사용함 - 입력 문장의 단어의 순서를 뒤집는 것이 굉장히 가치 있다는 것을 알아냈다.
> a, b, c : α, β, γ 가 아닌 c, b, a : α, β, γ로 매핑하는 것
> 이렇게 뒤집음으로써 SGD가 입력과 출력 사이의 커뮤니케이션을 쉽게 만들 수 있음
> 간단한 데이터 변형이 LSTM 성능 향상에 큰 도움을 줄 수 있었음
4. Experiments, 실험 결과
1) 데이터셋
- 문제 : WMT' 14 영어 -> 불어 기계번역
- 데이터셋 : WMT’ 14 영어-불어 데이터셋
- 16만 개의 빈도 높은 단어(소스 언어)와 8만개의 빈도높은 단어(타겟 언어)를 사용해 단어 사전 구성
2) Decoding and Rescoring
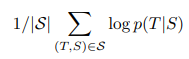
- log 확률을 최대화하도록 학습
- T : 올바른 번역
- S : 소스 문장
- left-to-right 빔 서치 디코더를 이용해 번역 문장을 생성한다.
- 각 단계마다 단어 사전의 모든 단어와 함께 빔의 부분 가설(번역 단어)을 확장한다.
- 확장된 가설 중 가장 가능성이 있는 번역이 log 확률에 따라 선택되며, 나머지는 버려진다.
- "<EOS>" 토큰 (End Of Sentence)이 번역에 더해지면 빔에서 제거 후 완성된 번역 문장에 더해진다.
- 디코더는 거의 정확한 반면에 시행하기에 간단하다.
- 빔 사이즈 1일 때 성과가 좋았으며 빔 사이즈 2는 빔 서치의 이점을 거의 다 제공한다.
- LSTM을 사용해 베이스라인의 1000개의 목록을 rescoring 했다.
- 모든 가설의 log 확률을 계산한 후 베이스라인의 점수와 LSTM의 점수의 평균을 취했다.
3) 문장 뒤집기
- 소스 문장을 뒤집어 학습함으로써 모델의 test perplexity(낮을수록 좋은 성능)가 5.8에서 4.7로 떨어지고, BLEU 스코어는 25.9에서 30.6으로 오르는 성과를 보여줌
- 문장을 뒤집음으로써 long term dependency 문제를 해결할 수 있다.
- 기존에는 minimal time lag 문제로 인해 소스 문장의 단어들이 그에 상응하는 타겟 문장의 단어와 거리가 멀었다.
- 소스 문장을 뒤집는다면, 평균적인 단어 간의 거리는 같지만 처음 나오는 몇 단어들이 타겟 문장의 단어와 매우 가깝기 때문에 minimal time lag 문제가 상당 부분 줄어들 수 있다.
반응형
'ML & DL > 논문' 카테고리의 다른 글
| [논문리뷰] 한국어 기술문서 분석을 위한 BERT 기반의 분류모델 (2) | 2021.07.02 |
|---|---|
| [논문리뷰] Research on Dynamic Political Sentiment Polarity Analysis of Specific Group Twitter Based on Deep Learning Method (2) | 2021.07.02 |